
Every word that AI generates or action it takes at the application level depends on a complex ecosystem extending far beyond the model itself.
NVIDIA CEO Jensen Huang calls this ecosystem a “five-layer AI cake.” His metaphor reframes AI as essential infrastructure, like the electricity or the internet, that extends deep into the physical world and requires careful orchestration between industries that have traditionally operated in silos. Whereas industrial factories transform energy and materials into finished goods, AI factories transform energy and raw data into intelligence at scale
The five layers span energy, chips, infrastructure, models, and applications, with each layer shaping the performance, scalability, and governance of the one above it. Huang argues that this requires an ecosystem in which every layer is built to reinforce the next.
When these layers are designed to work together, organizations can improve performance at scale, strengthen token economics, and reduce operational friction across the AI stack.
By contrast, fragmented AI infrastructure creates operational bottlenecks, increases costs, and makes governance harder to enforce consistently across environments. Flexera’s 2026 State of the Cloud Report found wasted cloud spend climbed to 29% this year, highlighting the growing cost complexity introduced by AI adoption and emerging IaaS and PaaS services. The FinOps Foundation has similarly reported that organizations are increasingly managing AI, SaaS, and private cloud costs across multiple disconnected environments, increasing operational complexity and governance overhead.
That’s the challenge Nscale is built to solve: fragmentation across every layer of the AI stack. Together with ecosystem partners across energy, compute, infrastructure, and models, Nscale integrates the stack through an interoperable, non-opinionated architecture built for reliable scale.
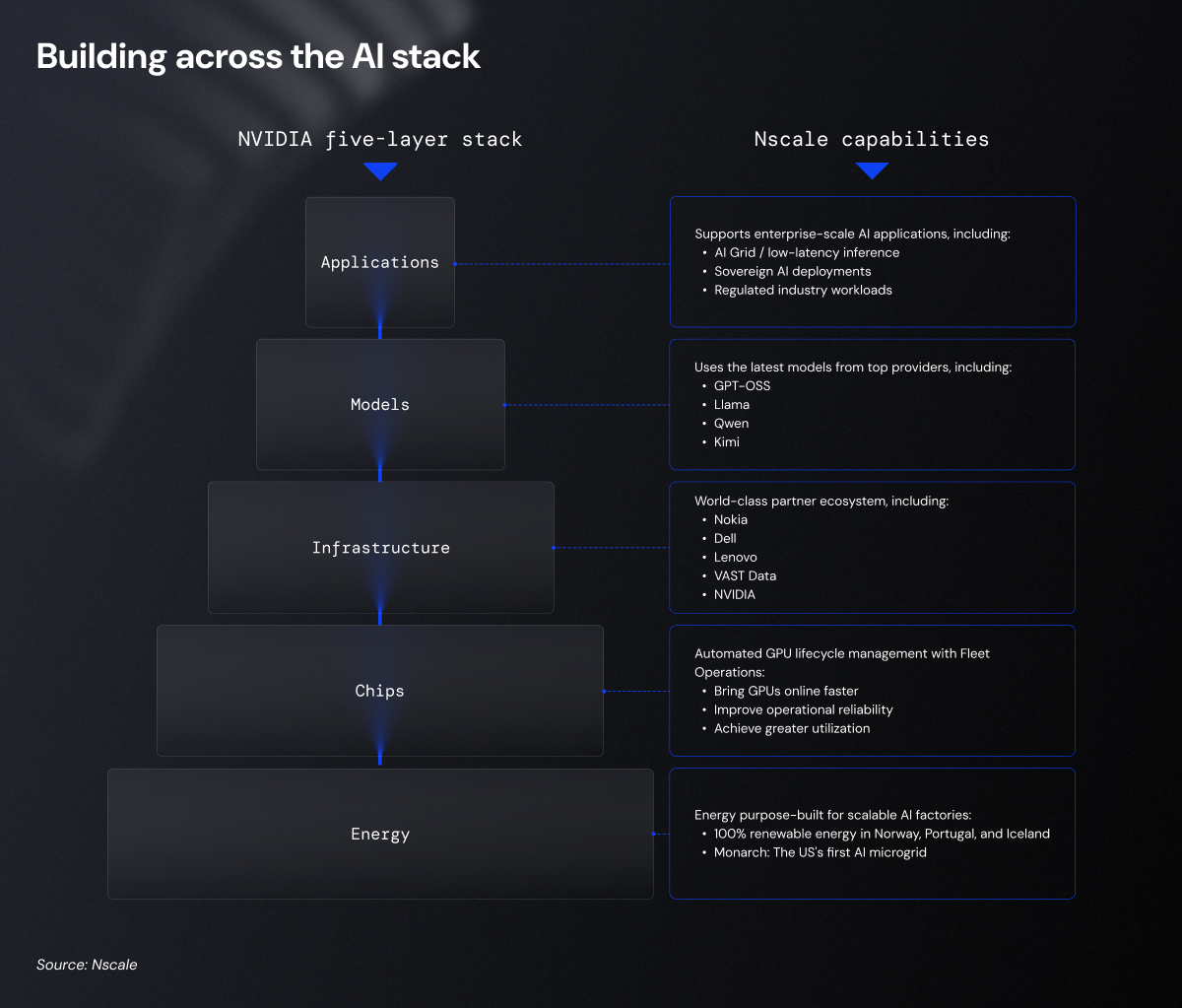
This is how that approach is applied in practice, starting from the foundation.
1. Energy is becoming AI’s defining constraint
Without energy, there is no AI, and at scale it becomes the critical constraint on growth. That's why energy is a core part of Nscale’s infrastructure strategy. This year, we acquired Monarch Compute Campus, a 2,250-acre site in West Virginia with on-site power generation of 1 GW, scalable to more than 8 GW. This commitment ensures an abundant, high-quality power supply that is independent of strained grid infrastructure and avoids competition with local power consumers.
In Europe, many of our data centers run on 100% renewable power. Cooling efficiency is improved through site selection, including Arctic Circle locations and sites that use naturally cold climates or ocean water for cooling. The result is reliable, scalable energy that underpins the entire stack and enables AI workloads to operate at scale. That reliability shapes the performance and economics of every layer above it.
2. The best chips only matter if they perform at scale
Producing intelligence in real time requires procuring the world's best chips, and getting the most out of each one. Nscale does both.
Our partnership with NVIDIA includes participation in two Nscale funding rounds as well as one of the largest global commitments to accelerated computing GPU infrastructure, spanning hundreds of thousands of GPUs. This includes the deployment of 66,000 NVIDIA Vera Rubin GPUs in Portugal, and 200,000 NVIDIA Blackwell Ultra GPUs across Europe and the US.
The value of those chips depends on how effectively they are deployed and operated. Nscale's Fleet Operations ensure every node is tested, provisioned, and performs efficiently with minimal human touch. Fleet operations automates the GPU hardware lifecycle from enrollment through maintenance, discovers hardware faults before they affect workloads, and tracks the health of every component in real time. That means our teams bring GPUs online faster, operate them with higher reliability, and maintain consistent performance across regions. The result is higher utilization and less downtime.
3. AI infrastructure works best as a coordinated system
Nscale's infrastructure goes beyond a network of data centers. It manages thousands of GPUs across sites as a single, coordinated operation.
Our facilities are purpose-built for AI, meaning we don't have to retrofit legacy hardware built to different specifications. High-density compute facilities are organized into scale units configured for specific workloads, such as training or inference, reducing unnecessary data movement. Optimized cluster layout and high-speed connections minimize communication overhead and improve fleet-wide efficiency. This enables unified inventory management, policy enforcement, and clear visibility of fleet-wide capacity, while preserving site-level controls.
Our partners strengthen this architecture. NVIDIA's InfiniBand and NVLink enable high-speed communication between GPUs. Nokia network connectivity links infrastructure across sites and regions. Dell's AI-optimized server architecture integrates compute, storage, and networking at the hardware level. Lenovo supports the deployment of repeatable cooling architecture that can be rapidly and cost-effectively replicated, and VAST Data’s unified storage platform delivers the high-throughput data layer that keeps GPUs fully utilized for training and inference.
This is how Nscale turns standalone infrastructure into a unified system that enables models and applications to scale more efficiently.
4. AI models are outpacing the systems built to run them
Models are advancing faster than the operational frameworks required to deploy and operate them, leaving a gap between what AI can do and what organizations can execute at scale.
As developers move from controlled experimentation into production-scale training and inference workloads, AI platform services present a trade-off: use managed services that boost speed but limit control, or build on raw infrastructure and face increased operational complexity. Nscale addresses this trade-off by allowing teams to abstract the infrastructure required to train and run models where needed, while retaining control over how they are developed, deployed, and operated.
We provide access to the latest models from leading providers, including OpenAI, Meta, and Qwen, which are available on demand through serverless inference, can be adapted to specific use cases through fine-tuning, and coordinated across environments through managed orchestration.
This enables teams to move from experimentation into production without taking on the operational burden of running the underlying systems.
5. AI needs infrastructure built for real-world constraints
The final layer is where tokens become productivity and revenue.
As AI applications move into production, infrastructure decisions increasingly shape cost, performance, governance, and user experience. Applications operating in real time or across regulated environments require infrastructure that can scale efficiently while meeting latency, sovereignty, and compliance requirements.
By building specifically for AI workloads, with high-bandwidth GPU interconnects, multi-rack architectures built for large-scale training, and modular data centre designs that support rapid scaling, Nscale helps organizations improve compute efficiency, maintain flexibility across models and deployment environments, and reduce the operational complexity of running AI at scale.
With the AI Grid, a coordinated network of centralized AI factories, regional hubs, and edge nodes, we're supporting a transition in the delivery of AI that will facilitate the next generation of AI applications, including robotics and self-driving vehicles. These types of applications will likely operate in real time, under strict latency requirements, and within specific regulatory and geographic constraints. This means moving AI to where the data is.
BT’s partnership with Nscale demonstrates how organizations are accelerating the delivery of sovereign AI infrastructure and scalable AI compute capacity in the UK, enabling organizations to meet regulatory, data residency, and security requirements while scaling AI capacity on demand.
Building for the whole AI factory
The five-layer AI cake describes much more than a new framework. It envisions a new industrial process, where the cost of every token reflects design decisions made with the full stack in mind.
Organizations operating within a single layer will face increasing constraints. Those who can harness the power of the whole AI factory, spanning applications, models, infrastructure, chips, and energy, will be able to scale more effectively and deliver better outcomes
Building for the entire AI life cycle requires more than procuring high-quality hardware or operating efficient data centers. It requires designing and operating every layer with the others in mind, so that nothing becomes a constraint on the infrastructure above it.
This is the shift Nscale and our ecosystem partners are built for.

.png)
.png)

