.jpg)
What does it really take to turn a powerful general-purpose language model into a domain expert? That’s where fine-tuning comes in. In this post, we’ll break down what fine-tuning is, why it matters, and how techniques like Supervised Fine-Tuning (SFT) are helping businesses build smarter, more specialised AI systems.
We’ll also introduce Nscale’s new fine-tuning service, a streamlined way to adapt LLMs quickly, securely, and effectively using your own data.
What is Fine-tuning an LLM?
Open-source Large Language Models (LLMs) like DeepSeek and Llama are incredibly powerful general-purpose text generators, but they are not born knowing the specifics of your tasks or industry. Fine-tuning is the process that bridges this gap. It takes a broad, pre-trained LLM and further trains it on task-specific or domain-specific data so the model learns to excel in your particular use case.
In essence, fine-tuning turns a generic language model into a specialised model, aligning it more closely with human expectations for a given application. This is hugely important for anyone looking to deploy LLMs in real-world scenarios because it lets you tailor the model’s knowledge, tone, and behavior to better fit your needs.
For example, a model like DeepSeek may come with broad, general-purpose language ability, but if a healthcare organisation fine-tunes it on thousands of medical reports and patient notes, it will become much more familiar with medical terminology and clinical language. After such fine-tuning, the model can assist doctors with detailed patient report generation far more accurately, because it has effectively absorbed domain knowledge from the medical dataset.
When we talk about fine-tuning, specially supervised fine-tuning, this usually means continuing a model’s training on a targeted dataset made up of labelled examples to improve performance on a specific task or within a particular domain. It’s essentially a supervised learning process: you provide examples of inputs (prompts) and the desired outputs (responses), and you adjust the model’s weights so that it reliably reproduces those outputs.
In practical terms, you might feed the model a prompt (say, a customer question) along with the correct answer it should output, and do this for hundreds or thousands of Q&A pairs. Over many training iterations, the model gradually minimises its errors on these examples and “learns” to respond correctly on its own. In this way, it starts to specialise in the patterns and requirements of your task, whether that’s customer service dialogue, medical report writing, legal contract analysis, or anything else.
Crucially, because the model isn’t starting from scratch but rather adapting its existing knowledge, fine-tuning is far more efficient than training a new model from the ground up. You can achieve strong results with relatively less data and compute time by leveraging what the model already “knows.” Instead of spending resources to train a brand new model, you begin with an existing one that already understands general language patterns, and then you simply teach it the nuances of your specific task.
Why Fine-tune LLMs for specific tasks?
Out-of-the-box LLMs are generalists, they’ve seen a bit of everything from internet text. But businesses and professionals often need models that act as specialists on their proprietary data, industry jargon, and style. Fine-tuning allows an LLM to become highly relevant and accurate for your domain.
Here are a few key reasons organisations fine-tune LLMs for their specific tasks:
- Domain Specificity: Fine-tuning teaches the model your industry’s jargon, terminology, and context so it produces content that’s highly relevant to your field.
- Improved Accuracy: Fine-tuning on domain-specific examples significantly boosts a model’s accuracy for your tasks. It reduces mistakes that a generic model might make in high-stakes scenarios (like medicine or law).
- Customised Tone & Interaction: Fine-tuning can imbue the model with your brand’s voice, tone, and style. The AI learns to follow your guidelines for communication, so its responses stay consistent with your brand’s persona.
- Data Privacy & Control: Fine-tuning uses your proprietary data in a controlled environment, so the model learns from your internal knowledge without exposing sensitive information. You gain tight control over what the model knows and says, reducing the risk of unintended leaks.
- Handling Edge Cases & Complex Tasks: Fine-tuning can include rare scenarios and even instill new problem-solving behaviors (like step-by-step reasoning or tool use) that a base model might struggle with. This makes the model more robust. When faced with a niche or complicated query, the fine-tuned model has seen similar examples and knows how to handle it.
- Overcoming Context Limitations: Fine-tuning also helps when including all relevant information in each prompt isn’t feasible due to context window limits or cost. By baking important domain knowledge into the model itself, you avoid extremely long prompts and reduce per-query processing costs.
In short, while base LLMs offer broad knowledge, fine-tuning sharpens an LLM’s capabilities to fit the unique contours of your business’s needs, yielding more precise and reliable results for the task at hand. It’s how you get an AI model that isn’t just smart in general, but smart about your problems.
Approaches to Fine-tuning and aligning LLMs
Over the past couple of years, the AI community has developed a few different approaches to fine-tune or further train LLMs to better align with what humans want.
The main approaches include Supervised Fine-Tuning (SFT), Reinforcement Learning from Human Feedback (RLHF), the newer Direct Preference Optimization (DPO), and a recent addition known as Group Relative Policy Optimization (GRPO). Each method has its own use cases, complexity, and advantages.
Below is a brief overview of SFT, RLHF, DPO, and GRPO, including the data they require, how they work, and their benefits and limitations:
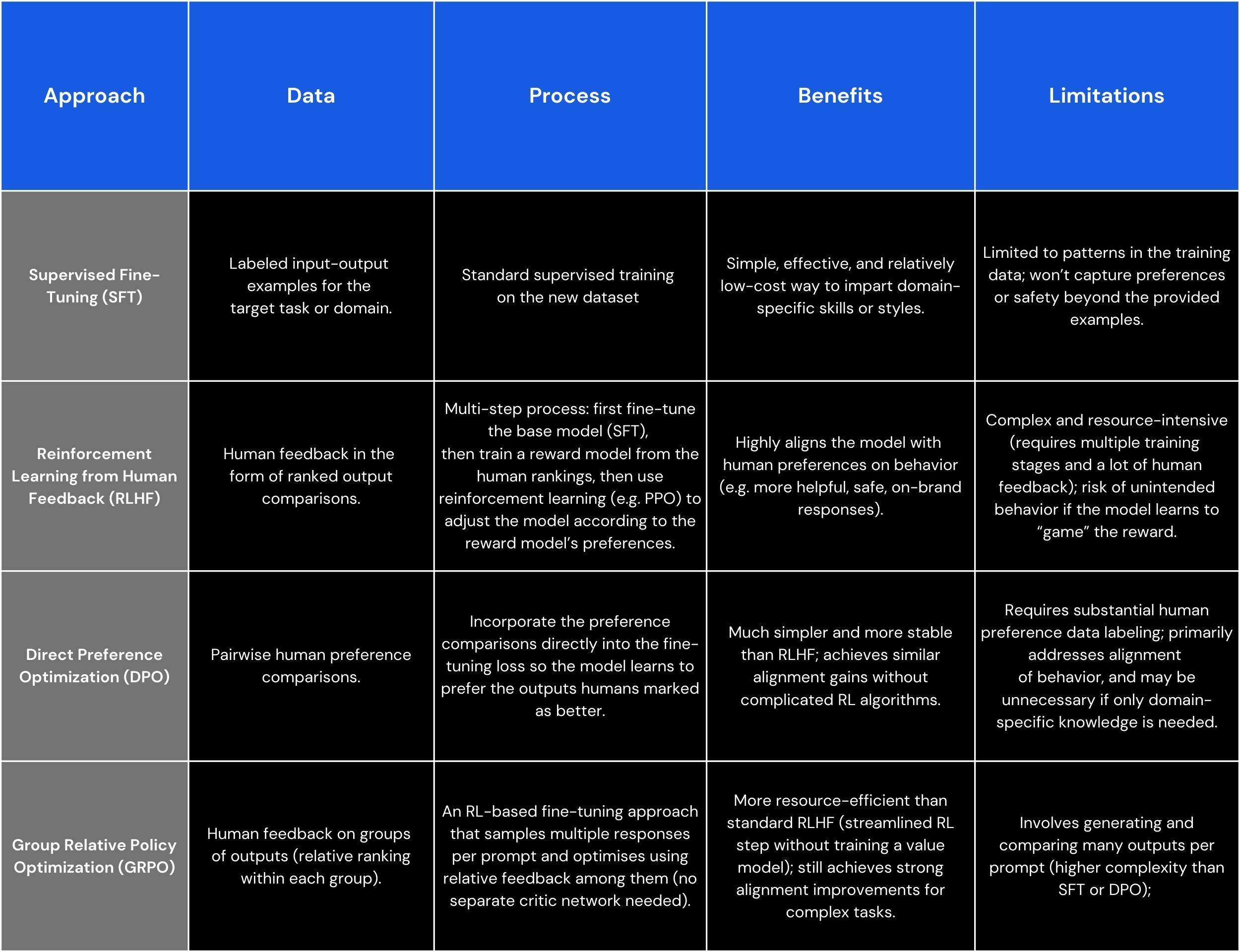
SFT vs. RLHF vs. DPO vs. GRPO: Which approach is best for your needs?
Now that we’ve outlined these approaches, let’s compare them in terms of simplicity, cost, and effectiveness, especially from a business perspective:
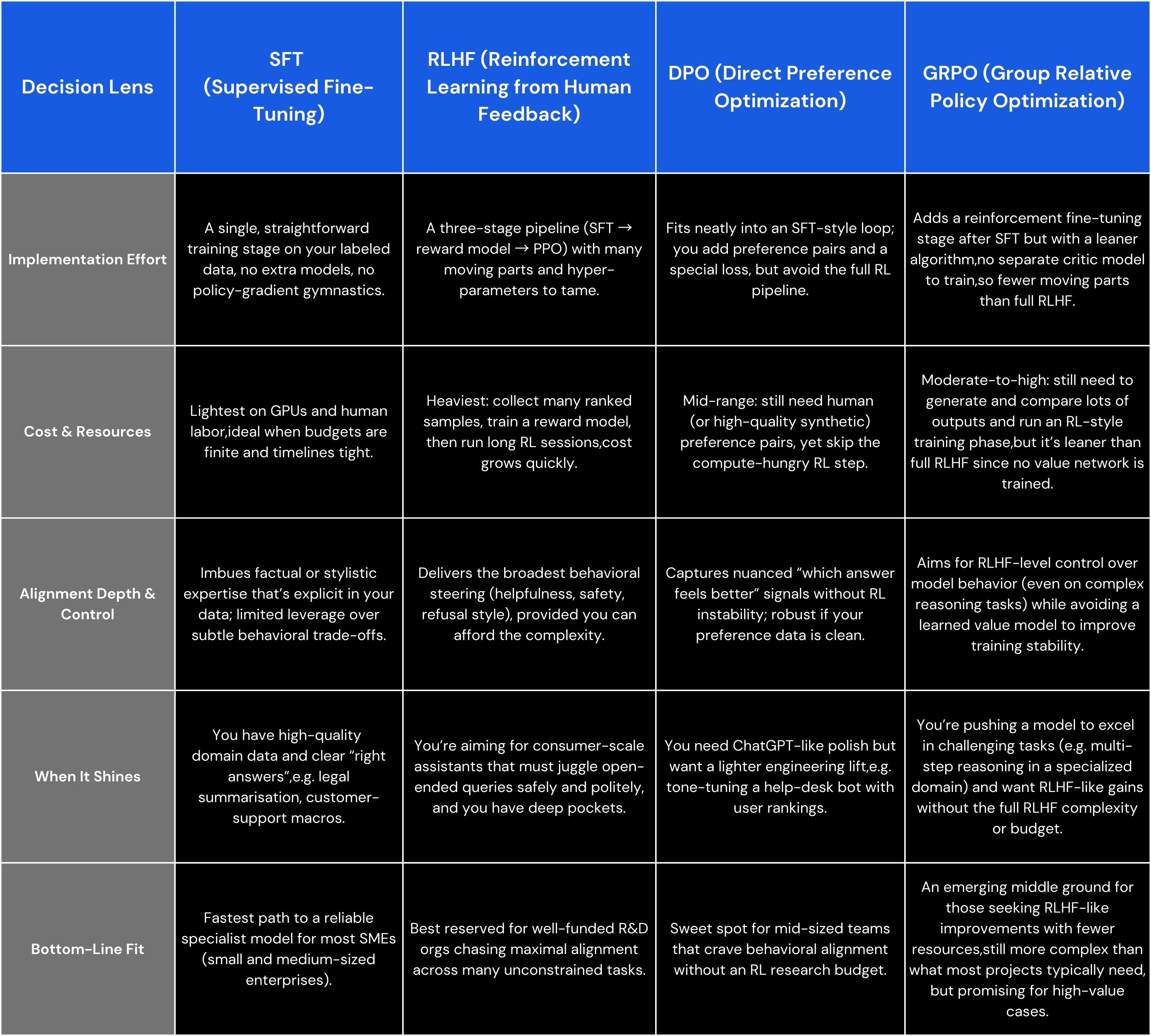
For most organisations that have proprietary data and a clear task in mind, Supervised Fine-Tuning is the go-to approach. It’s the foundation upon which other methods build, and it usually delivers the biggest immediate improvement with the least complexity.
RLHF, DPO, and newer techniques like GRPO are powerful but tend to be the domain of AI labs or specialised needs, whereas SFT is accessible to businesses large and small to make an LLM their own.
When is SFT the best choice? Real-world examples
To illustrate how supervised fine-tuning works in practice and when it shines, let’s look at a couple of real-world inspired scenarios:
Healthcare Assistant:
Imagine a hospital system has a large database of medical records, diagnoses, and treatment recommendations. By fine-tuning an LLM on this medical data, the model can learn to understand clinical terminology and provide answers consistent with medical best practices. For example, it will pick up the meaning of terms like “HbA1c” or “metoprolol” and learn the style of writing doctor’s notes.
After SFT, if a doctor asks the model for help summarising a patient’s case or suggesting potential diagnoses, the model’s responses will be far more accurate and detailed, using the proper medical language and reasoning. In fact, a model fine-tuned for the medical domain develops enhanced capability with medical concepts and jargon that a general model might struggle with. SFT is the best choice here because we have authoritative data (the hospital’s own knowledge) and we need factual, safe outputs; the fine-tuned model becomes a specialised medical assistant.
Financial Assistant:
A financial services firm wants to use LLMs to support internal analysts and customer-facing teams with timely, accurate insights. They have large repositories of earnings reports, investment memos, regulatory filings, and past market analyses. By fine-tuning an LLM on this proprietary data, the model begins to learn not just financial terminology, but how the firm evaluates risk, interprets market events, or summarises performance across portfolios.
Post fine-tuning, the model can assist analysts by drafting sections of earnings summaries, helping compliance teams spot reporting anomalies, or generating client-facing portfolio reviews that align with internal standards. Because the fine-tuning data reflects the firm’s own judgment, templates, and language, the model naturally adapts to how the business operates.
This is another case where SFT shines: it enables a general LLM to become a sharp, well-briefed financial assistant that mirrors the tone and logic of your institution, without handing over sensitive documents to an external service.
Customer Support Chatbot:
Consider a company with a trove of customer support transcripts and FAQ answers. They want a chatbot that can handle customer questions just like their human agents, in the same friendly tone and with up-to-date product knowledge.
By fine-tuning a model on those customer support transcripts, the model will learn the company’s preferred greetings, style of answering, and solutions to common problems. It will also incorporate the company’s proprietary product info that may not appear in any public training data.
After SFT, the chatbot can respond with the correct details (e.g. pricing, troubleshooting steps specific to the company’s product) and do so in a manner consistent with the brand’s voice and tone. This is a case where SFT is clearly the best approach; the company has high-quality Q&A data, and applying supervised training will directly impart that knowledge and style to the model. There’s no need for the complexity of RLHF because the desired responses are already known and can be taught directly. Additionally, fine-tuning on the company’s own data ensures that no sensitive customer information leaves their environment, and the model won’t hallucinate answers, it will stick to the answers it was trained on.
In each of the above examples, supervised fine-tuning is the hero: it uses ground truth examples from the domain to sculpt the model’s behaviour. When you have clarity on what outputs are correct or desirable (as is the case in most business applications), SFT tends to be the most efficient and effective path to get a model that does exactly what you want.
Nscale’s new Fine-tuning service: Fast-track your LLM adaptation
The growing demand for custom LLMs has led to new tools and services that make fine-tuning more accessible. Nscale’s fine-tuning service starts with Supervised Fine-Tuning, the straightforward way to train a model on your proprietary data while keeping that data firmly inside your own environment. Additional methods, DPO, GRPO, and others, are on the roadmap, so teams will be able to move to more advanced alignment techniques as their requirements expand.
Nscale provides an AI cloud platform with a robust GPU infrastructure. This means businesses can bring their domain-specific dataset, select a base model, and quickly obtain a fine-tuned model without having to manage the heavy lifting themselves. Because Nscale’s service relies on SFT, it leverages your labeled examples directly, no complex RL or extra reward models in the loop, which keeps the process straightforward and cost-effective for business use cases.
Security is a top priority in Nscale’s fine-tuning pipeline. Your data stays within a controlled environment, and the fine-tuning process is set up so you retain full control over the model and the training data. This means you can confidently fine-tune on sensitive internal data (contracts, internal support tickets, etc.) knowing it won’t be exposed to outside systems.
The service is built for speed and visibility. Powered by Nscale’s high-performance GPU clusters and tuning know-how, a run that might monopolise your own hardware for days can wrap up in hours, getting new models into production sooner. At the same time, you can follow every job in real-time, monitoring metrics, reviewing metrics, and stepping in to tweak parameters whenever you like. Because the entire pipeline is automated and scales on demand, teams can spin up multiple experiments, mixing datasets, hyper-parameters, or different open-source base models, and iterate without wrestling with infrastructure.
Whether you’re aiming to build a medical AI assistant, a legal document AI, a bespoke chatbot, or any other specialised LLM, supervised fine-tuning is the key, and with the right platform, it’s a key you can turn with confidence to unlock powerful results.
Interested in trying it out?
Nscale’s fine-tuning offering is now available for customers looking to quickly tailor LLMs to their needs. You can learn more about this service (and see how it can unlock the full potential of your AI projects) on the Nscale fine-tuning page.
.png)





