
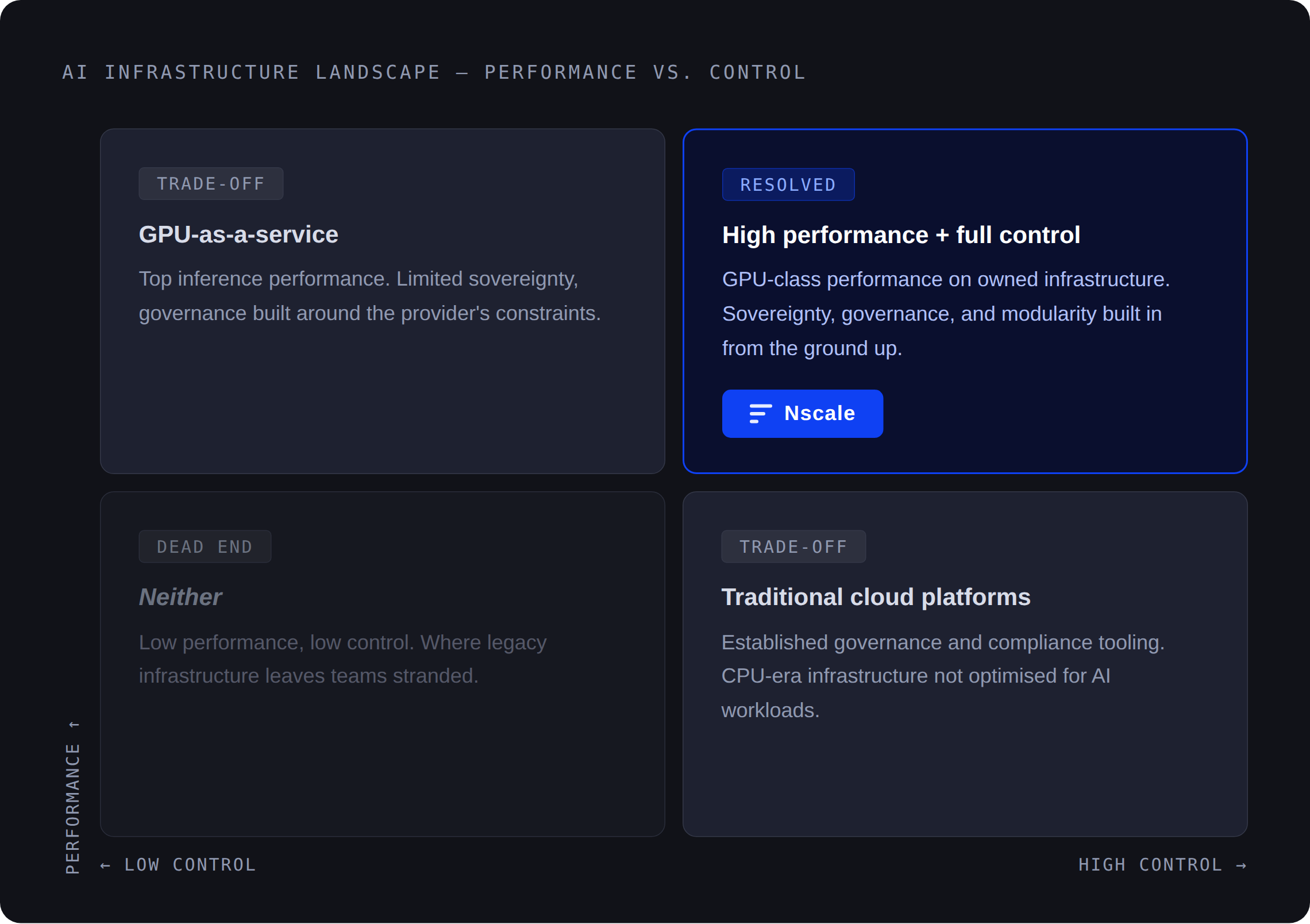
AI developers and engineers are being forced into a trade-off that shouldn’t exist: move fast with managed AI services and give up control, or build on raw infrastructure and absorb the full cost of complexity.
This is becoming one of the defining bottlenecks of enterprise AI adoption.
Enterprise spending on generative AI has more than tripled year-over-year, while token usage and inference demand are growing at unprecedented rates. Gemini alone saw token usage increase 50x and inference is expected to account for more than half of total AI compute by 2030, according to McKinsey. At the same time, studies from firms like Deloitte consistently point to the same constraint: the gap between experimentation and production remains the hardest part of deploying AI at scale.
Teams can prototype quickly, but turning those prototypes into reliable, cost-efficient, and governed systems is still slow, expensive, and operationally complex. For enterprises, that challenge is compounded by the need to meet sovereignty and compliance requirements without sacrificing performance.
The result is a structural mismatch. Model capability is accelerating. Enterprise infrastructure and enterprise tooling are not keeping pace, while sovereignty and compliance concerns continue to grow.
For engineering teams, that mismatch shows up in very real ways:
- Environments designed for CPU workloads that are not cost effective for GPU workloads
- Cost of hardware and rate of change mean that they need to compromise in performance and even worse, the value they get out of AI
- Weeks spent stitching infrastructure and keeping up with rapidly evolving AI tooling, dependencies, hardware, and models instead of shipping features
- Limited flexibility in managed platforms that do not fit production requirements
- Inference costs that scale faster than the value they produce
As AI moves from experimentation to core business systems, this trade-off is no longer acceptable.
And it points to a deeper shift: AI services are about how quickly and reliably models can be deployed, operated, and improved in production. The question is no longer how to access AI. It is how to deploy it without compromise and how to seamlessly integrate it with enterprise compliance and security whilst addressing new daily business requirements.
Purpose-built infrastructure changes that equation: deployments like Nvidia’s Vera Rubin platform show that it is possible to deliver both, operating within sovereign constraints while maintaining the performance needed for production AI.
The trap most platforms set
Most AI services platforms present engineering teams with a version of the same trade-off: convenience at the cost of control, or control at the cost of time or development.
Both ultimately show up in token economics.
Fully managed platforms move fast. They abstract the infrastructure, simplify the API surface, and compress the distance between first call and initial result often aligning well with how enterprises prefer to build, test, and deploy applications, with governance and cost visibility built in. But they also constrain model selection, limit customization, and build structural dependency into every deployment decision impacting direct total cost of ownership.
For teams integrating AI into complex enterprise systems, where compliance varies by geography and requirements evolve rapidly, that rigidity is not a minor inconvenience. It is an operational challenge with evolving location specific expectations about data process, storage, decisions, and deployments. Without intentional design, it can become a liability and business risk.
The alternative, vertically optimizing each layer for governance, security, sovereignty and obviously performance, inverts the problem into an accelerated path to value. Total flexibility, but at the cost of time and significant engineering investment. Governance, isolation, and reliability still need to be engineered, not assumed.
Token economics deepens the challenge.
As token volumes continue to scale, teams are not only increasing what they put into these models, but also placing greater expectations on the value and quality of what comes out. Cost per useful output is becoming as strategically significant as raw model capability.
A platform that is fast but expensive, or affordable but unreliable, fails the same test from different directions. This is the core failure mode of current AI services: every path forces a compromise.
Building blocks instead of black boxes
The trade-off is not inevitable. The solution is a different design philosophy: build the foundation, design the components and the seams between them to be sovereignty aware, composable by design, and optimized for top performance, and let engineering teams compose from it.
Where most platforms force a choice between convenience and raw flexibility, Nscale removes that constraint by exposing modular, interoperable building blocks. Because clients have a wide range of differing needs, the approach is to offer a flexible set of core building blocks that allow them to work quickly and tailor solutions in whatever way suits them best.
This is how speed and control stop being opposing forces. Teams can move quickly without being locked into predefined workflows, and retain architectural flexibility without rebuilding infrastructure. This allows both experienced AI engineers and newcomers to AI to work from the same interface. We offer the ability to drill down to the lowest levels of control, while also providing easy-to-use abstractions.
Nscale’s AI services portfolio is structured around this principle. Three current core services form the foundation: Inference, Fine-tuning, and the Prompt Workbench.
Together, we aim to build a system that spans the full lifecycle from experimentation to production without introducing friction between stages.
- Inference provides access to open-source models across text, multimodal, and image generation workloads.
- Fine-tuning enables domain-specific adaptation, aligning models to enterprise data without requiring full retraining.
- The Prompt Workbench introduces a structured layer for evaluation, allowing teams to test and validate configurations before production.
Instead of choosing between speed and control, teams can iterate quickly, validate decisions systematically, and deploy with confidence.
Nscale also applies these building blocks internally to operate and optimize deployment workflows in real-world conditions. Previously, teams had to sift through large volumes of logs to identify where issues were occurring. Now, that process is handled by AI, which analyzes the data and produces a failure report, cutting debugging time from 10 to 30 minutes down to about a minute.
Inference performance is a system problem
Resolving the trade-off requires rethinking how inference is designed.
Key-value (KV) cache stores intermediate attention states, allowing models to process long contexts without recomputing earlier tokens, reducing both latency and most importantly overall time and cost. For most providers, this is a background optimization. At Nscale, it is a design constraint that shapes routing, scaling, and cost.
KV cache is treated as a core, first-class component within the system.
That design shows up in three ways:
- KV cache-aware routing avoids unnecessary recomputation
- KV cache offloading preserves performance for long-running workloads
- Disaggregated inferencing separates prefill and decode for independent scaling
The system delivers strong latency performance even at high throughput, but that alone does not determine its overall value. Its economic viability ultimately depends on the underlying infrastructure, where data centers convert inputs such as prompts and power into generated tokens.
Because Nscale owns its data centers and energy supply, the system is optimized for both performance and cost. The result is not just faster inference, but more affordable inference at the unit level that matters.
Total cost of ownership is a critical consideration, with energy playing a central role. By securing power capacity in advance and planning for future expansion, the aim is to stay ahead of demand while maintaining fair token pricing over time.
As inference scales, performance and cost can no longer be separated. In fragmented systems, they diverge. In integrated systems, they compound. This is how performance and cost stop being opposing forces.
Security and sovereignty without friction
Governance is often treated as a separate concern in AI infrastructure. In practice, it becomes another version of the same trade-off.
Move fast, and governance becomes a risk. Retain control, and deployment slows down. Enterprise AI deployments carry real constraints: data residency, compliance, and auditability. If they are not built into the system, they become a blocker.
The approach is the same as in performance and control: make governance part of the foundation. Nscale’s serverless inference is designed with strict tenant isolation by default.
For regulated organizations, this removes an entire class of architectural work. Governance is not something teams need to design around. It is already enforced. Security and sovereignty are central to the Nscale value proposition, with a focus on working closely with customers to understand their specific governance requirements and embedding those needs directly into the product.
Governance should not slow teams down. It should enable them to move with confidence. In systems where governance is layered on, speed and compliance are in tension. In systems where it is built in, they scale together.
The foundation that earns speed
Deploying AI reliably, cost-effectively, and with proper governance requires infrastructure thinking alongside model thinking.
The teams that move fastest are not those that selected the most opinionated platform. They are those with the right foundation: modular, well-engineered systems that hold up in production.
Platforms that force trade-offs will continue to slow teams down. The next generation of AI services will remove those trade-offs by design to generate compounding impact.



.png)
.png)

